I had just finished taking a MOOC hosted by Andrew Ng on machine learning. One of the topics covered in that course was the concept of neural networks. Briefly, the neural network is a machine learning technique in which one attempts to computationally model the human brain, and use that model to make decisions. While there are many different models in use today, the course focused on one of the simpler models - the multilayer perceptron (MLP).
In this model, we have layers of “neurons”, which are abstracted as the circles in the diagram below. The output from each circle is fed into the inputs of every neuron on the next layer, creating this network of dataflow. Input data presented to the network is input at the left-hand side, and the outputs are eventually grabbed from the right hand side.
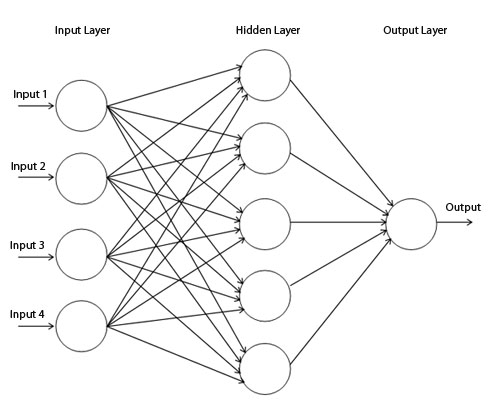
When evaluating this model on a computer, the output for each neuron, the “activation level”, must be handled sequentially. This is a heavy computational load - sums must be computed again and again and again! Old results can’t be cached and re-used, due to the fact that there are different weighting coefficients applied to the inputs that differ from neuron to neuron. This can make a neural network very slow on a general-purpose processor.However, after staring at the network, one realizes that this process should be trivially parallelizable. This seems like a perfect task for a Field Programmable Gate Array (FPGA)! The problem is that developing code to program FPGAs is very different from any software language, making it very difficult for those from a traditional machine learning background to create special purpose hardware for their developed neural networks.
This project attempts to bridge that knowledge gap by providing a simple, clean Graphical User Interface (GUI) that lets the user generate customized VHDL files that implement neural networks. The GUI, written in C#, will allow the user to input important parameters such as the number of hidden layers, the activation functions of the neurons in a given layer, and whether the output will be a classifier output or a regressive output. The GUI will allow the user to select from a few different layout schemes and fixed point bus widths, allowing the user to trade execution speed for FPGA chip space to fit their needs. The goal of this program is to allow for a user to easily take an algorithm developed using MATLAB or some other software program and quickly translate it into a
hardware implementation. This would have massive effects on the area of robotics, “smart” devices, and embedded systems in general.
A rudimentary scheme has been implemented for neurons and sigmoid activations. The network is very fast, but takes up a large amount of chip space. The pipelined implementation is slower, but takes up a much smaller footprint. If possible, I highly recommend using the pipelined implementation. The code can be downloaded from github.